PDF Search Engine with Pdftools Conversion Service and Elasticsearch

What is the Pdftools Conversion Service?
The Pdftools Conversion Service is a scalable, on-premise or cloud-deployable solution (EC2, Azure) for automated document conversion and processing. It supports multiple integration options, including file system, email, and REST API. Some of the key features include converting various document formats (DOCX, XLSX, PDF, images, HTML) into archive-ready PDF/A, support for Linux (with Docker) and Windows, and scalability with platforms like OpenShift and Kubernetes.
For more information visit the Pdftools Conversion Service Product Summary or have a look at the Getting Start Guides. Feel free to contact us for more information.
Important Note: The code samples provided here are for demonstration purposes and learning. While we strive to maintain these examples, they are not officially supported. For production use, please refer to our official documentation.
Introduction
Managing and searching through large archives of PDF documents can be a challenging task. Pdftools Conversion Service, combined with Elasticsearch, offers a powerful solution to this problem by enabling full-text search, metadata filtering, and seamless PDF archiving. This tutorial introduces a project that demonstrates how to build a simple yet effective PDF search engine using these tools.
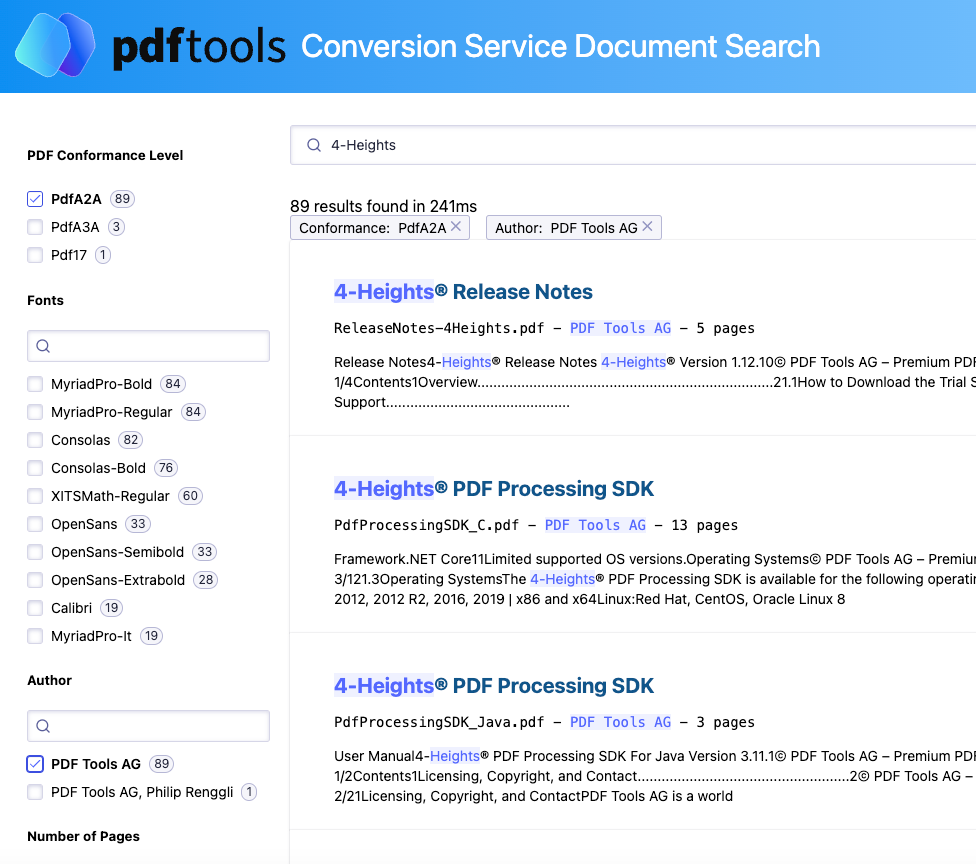
The project includes:
- PDFIngestor – A C# application that processes PDF files by extracting text and metadata, then indexes them into Elasticsearch.
- Search Frontend – A modern React-based search interface built with Next.js and powered by Searchkit for filtering and faceted search.
- Elasticsearch Guide - A step-by-step guide to get up and running with Elasticsearch in your development environment.
Source Code
The complete source code for this product is available in our GitHub repository: 🔍 PDF Search Engine with Pdftools Conversion Service and Elasticsearch.
See also Monitoring Pdftools Conversion Service Logs with ELK Stack.
Key Use Cases
-
Understand Your PDF Archives – Want to know exactly what’s in your PDF/A archive? This project lets you index and search PDF contents, extracting key metadata such as authors, number of pages, and fonts.
-
Search Across Multiple Document Types – The Pdftools Conversion Service can handle Word, Excel, PowerPoint, images, and more, converting them into PDF for a uniform and consistent search experience.
-
Efficient Document Management – Struggling to search a large archive of PDFs? Elasticsearch and Kibana offer robust filtering and analytics, making it easy to manage and retrieve documents.
By using Elasticsearch as a scalable and powerful search engine, combined with Pdftools Conversion Service to standardize document formats into PDF, developers can create efficient solutions for:
- Archiving government and corporate records
- Legal document management
- Cataloging research papers
How It Works
The architecture of the project is straightforward:
- Documents are processed by Pdftools Conversion Service and converted to PDFs.
- The PDFIngestor extracts text and metadata from the PDFs.
- Extracted data is indexed in Elasticsearch for fast, searchable access.
-
A React-based frontend powered by Searchkit allows users to search, filter, and visualize the documents.
(Incoming Documents) --> [Pdftools Conversion Service] --> (Converted PDFs) --> [PDFIngestor] --> (PDF to Text and Metadata) --> [Elasticsearch] <-- [React Frontend]
Getting Started
For full instructions on how to set up Elasticsearch, run the PDFIngestor, and deploy the frontend, visit the GitHub repository: https://github.com/pdf-tools/pdf_code_samples/tree/main/elasticsearch
This project is an excellent starting point for developers looking to build document search engines and explore the power of Elasticsearch combined with Pdftools Conversion Service.